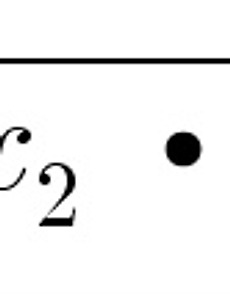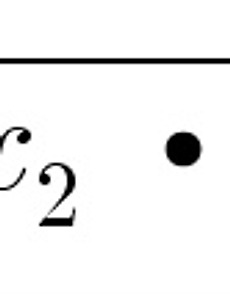 [Statistics, 통계] 기하평균(geometric mean)
예를 들어 2, 5, 7, 8 처럼 양수값들이 n개가 있을 경우에 이 값들의 곱의 n제곱근을 기하평균(geometric mean)이라 한다. sas에서 기하평균을 구하는 방법 참조 www.sasbigdata.com/80 [기하평균의 공식] 실제로 공학용 계산기를 이용하여 2, 5, 7, 8에 대해서 기하평균을 구하여 보자. 값이 2, 5, 7, 8로 n의 갯수가 4이다. 기하평균값은 약 4.86이 나왔다. [기하평균과 산술평균의 관계] 위의 공식을 보면 기하평균(geometric mean)은 산술평균(arithmetic mean)보다 크지 않음을 알 수가 있다. 위의 값으로 실제로 구해봐도 2, 5, 7, 8의 기하평균은 약 4.86 산술평균은 5.5로 기하평균은 산술평균보다 크지 않다. [기하평균은 왜..
2014. 2. 26.
[Statistics, 통계] 기하평균(geometric mean)
예를 들어 2, 5, 7, 8 처럼 양수값들이 n개가 있을 경우에 이 값들의 곱의 n제곱근을 기하평균(geometric mean)이라 한다. sas에서 기하평균을 구하는 방법 참조 www.sasbigdata.com/80 [기하평균의 공식] 실제로 공학용 계산기를 이용하여 2, 5, 7, 8에 대해서 기하평균을 구하여 보자. 값이 2, 5, 7, 8로 n의 갯수가 4이다. 기하평균값은 약 4.86이 나왔다. [기하평균과 산술평균의 관계] 위의 공식을 보면 기하평균(geometric mean)은 산술평균(arithmetic mean)보다 크지 않음을 알 수가 있다. 위의 값으로 실제로 구해봐도 2, 5, 7, 8의 기하평균은 약 4.86 산술평균은 5.5로 기하평균은 산술평균보다 크지 않다. [기하평균은 왜..
2014. 2. 26.
 [SAS] sas if문과 substr함수를 이용하여 관측치 일부분 수정하는 방법
sas에서 if문과 substr함수를 이용하여 관측치 일부분 수정하는 방법을 알아보자. 먼저 샘플데이터가 필요하므로 ace라는 간단한 데이터셋을 생성하였다. [코딩과정] data ace1; set ace; new_a=a; if substr(new_a,1,1)='A' then substr(new_a,6,1)=1 ; else if substr(new_a,1,1)='B' then substr(new_a,6,1)=2; if substr(new_a,1,1)='A' then substr(new_a,1,1)=0; else if substr(new_a,1,1)='B' then substr(new_a,1,1)=0; run; [설명] a변수를 new_a라는 변수로 하나 더 생성 한것은 한눈에 비교하기 쉽고자 생성하였다. ..
2014. 2. 21.
[SAS] sas if문과 substr함수를 이용하여 관측치 일부분 수정하는 방법
sas에서 if문과 substr함수를 이용하여 관측치 일부분 수정하는 방법을 알아보자. 먼저 샘플데이터가 필요하므로 ace라는 간단한 데이터셋을 생성하였다. [코딩과정] data ace1; set ace; new_a=a; if substr(new_a,1,1)='A' then substr(new_a,6,1)=1 ; else if substr(new_a,1,1)='B' then substr(new_a,6,1)=2; if substr(new_a,1,1)='A' then substr(new_a,1,1)=0; else if substr(new_a,1,1)='B' then substr(new_a,1,1)=0; run; [설명] a변수를 new_a라는 변수로 하나 더 생성 한것은 한눈에 비교하기 쉽고자 생성하였다. ..
2014. 2. 21.