 [SAS] substr 함수
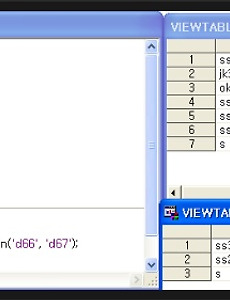
[코딩] data a; input k$ j h$; cards; ss30 1 d66 jk30 1 d1 ok2 1 dd9 ss27 2 d67 ss 1 d3 ss 1 dd5 s 3 d67 ; run; data b; set a; if substr(k,1,1)='s' & substr(h,1,3) in('d66', 'd67'); run; [해석] a라는 데이터가 있다. a데이터의 k변수 관측치가 s로 시작되는 것중에 h변수 관측치가 d66, d67로 시작되는 것만 추출하여라. 함수 : substr 목적 : 부분 문자열을 추출하거나 문자 값을 대체 할 수 있다. if substr(k,1,1)='s' & substr(h,1,3) in('d66', 'd67'); - k변수의 1번째자리부터 1번째자리가 s인 값을 추출하며..
2013. 10. 14.
[SAS] substr 함수
[코딩] data a; input k$ j h$; cards; ss30 1 d66 jk30 1 d1 ok2 1 dd9 ss27 2 d67 ss 1 d3 ss 1 dd5 s 3 d67 ; run; data b; set a; if substr(k,1,1)='s' & substr(h,1,3) in('d66', 'd67'); run; [해석] a라는 데이터가 있다. a데이터의 k변수 관측치가 s로 시작되는 것중에 h변수 관측치가 d66, d67로 시작되는 것만 추출하여라. 함수 : substr 목적 : 부분 문자열을 추출하거나 문자 값을 대체 할 수 있다. if substr(k,1,1)='s' & substr(h,1,3) in('d66', 'd67'); - k변수의 1번째자리부터 1번째자리가 s인 값을 추출하며..
2013. 10. 14.











